Teradata
FastLoad is a command-driven utility which can be used to quickly load
large amounts of data in an empty table on a Teradata Database. Part of
this speed is achieved because it does not use the Transient Journal.
But, regardless of the reasons that it is fast, know that FastLoad was
developed to load millions of rows into empty Teradata tables. FastLoad
loads data into EMPTY Teradata tables in 64 K Blocks. The only command
FastLoad understands is INSERT!
Data can be loaded from
- Disk or tape files on a mainframe-attached client system
- Input files on a network-attached workstation
- Special input module (INMOD) routines written to select, validate, and preprocess input data
- Any other device providing properly formatted source data
Teradata
FastLoad uses multiple sessions to load data. However, it loads data
into only one table on a Teradata Database per job. To load data into
more than one table in the Teradata Database, multiple Teradata FastLoad
jobs must be submitted, one for each table.
Fast load Restriction
- Only Primary Index is allowed in Fast Load.
- No Secondary Indexes are allowed on the Target Table.
- No Referential Integrity is allowed. FastLoad cannot load data into tables that are defined with Referential Integrity (RI). This would require too much system checking to prevent referential constraints to a different table. In short, RI constraints will need to be droped from the target table prior to the use of FastLoad.
- No Triggers are allowed at load time. FastLoad is much too focused on speed to pay attention to the needs of other tables, which is what Triggers are all about. Simply ALTER the Triggers to the DISABLED status prior to using FastLoad.
- No AMPs may go down (i.e., go offline) while FastLoad is processing. The down AMP must be repaired before the load process can be restarted.
- No more than one data type conversion is allowed per column during a FastLoad. Why just one? Data type conversion is highly resource intensive job on the system, which requires a "search and replace" effort. And that takes more time.
- Loads data in 64K blocks and only 30 FastLoad and MultiLoad combinations can run simultaneously.
Teradata FastLoad supports the following data formats:
- Formatted
- Unformatted
- Binary
- Text
- Variable-length text
Two Phases of Fast Load
- Acquisition Phase
- Application Phase

The
job of Phase 1 is to get the data off the mainframe or server and move
it over the network inside Teradata. The data moves in 64 K blocks and
is stored in worktables on the AMPs.
The data rows are not on the correct AMP yet! When all of the data has been moved from the server or mainframe flat file then each AMP will hash its worktable rows so each row transfers to the worktables on the proper destination AMP.
.
Acquisition Phase
The
primary function of Phase one is to transfer data from the host computer
to the Access Module Processors (AMPs) as quickly as possible. For the
sake of speed, the Parsing Engine of Teradata does not take the time to
hash each row of data based on the Primary Index. That will be done
later. Instead, it does the following:
- When the Parsing Engine (PE) receives the INSERT command, it uses one session to parse the SQL just once. It then opens a Teradata session from the FastLoad client directly to the AMPs. By default, one session is created for each AMP.
- Therefore, on large systems, it is normally a good idea to limit the number of sessions using the SESSIONS command. Simultaneously, all but one of the client sessions begins loading raw data in 64K blocks for transfer to an AMP. The first priority of Phase 1 is to get the data onto the AMPs as fast as possible. To accomplish this, the rows are packed, unhashed, into large blocks and sent to the AMPs without any concern for which AMP gets the block.
- The result is that data rows arrive on different AMPs than those they would live, had they been hashed. So how do the rows get to the correct AMPs where they will permanently reside? Following the receipt of every data block,each AMP hashes its rows based on the Primary Index, and redistributes them to the proper AMP. At this point, the rows are written to a worktable on the AMP but remain unsorted until Phase 1 is complete.
Phase
1 can be compared loosely to the preferred method of transfer used in
the parcel shipping industry today. How do the key players in this
industry handle a parcel? When the shipping company receives a parcel,
that parcel is not immediately sent to its final destination. Instead,
for the sake of speed, it is often sent to a shipping hub in a seemingly
unrelated city. Then, from that hub it is sent to the destination city.
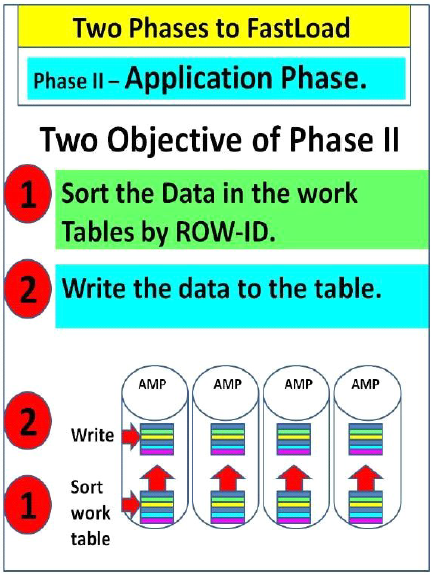
Application Phase
The shipping vendor must
do more than get a parcel to the destination city. Once the packages
arrive at the destination city, they must then be sorted by street and
zip code, placed onto local trucks and be driven to their final, local
destinations. Similarly,
FastLoad’s Phase 2 is mission critical for getting every row of data to
its final address (i.e., where it will be stored on disk). In this
phase, each AMP sorts the rows in its worktable. Then it writes the rows
into the table space on disks where they will permanently reside.
Rows
of a table are stored on the disks in data blocks. The AMP uses the
block size as defined when the target table was created. If the table is
Fallback protected, then the Fallback will be loaded after the Primary
table has finished loading. This enables the Primary table to become
accessible as soon as possible.
A Sample FastLoad Script
The
following page shows you an example of a FastLoad script. This script
is designed to INSERT into an empty Teradata table called
Employee_Table. This table exists in the database SQL01. FastLoad will
first logon. Then it will build the table structure (unless it already
exists and is empty). Then it will beginloading, but it will always
define two error tables. A checkpoint is optional. Then the INSERT is
performed and we are done.

How to write Fast Load Script?
Section 1
In
this section we give the LOGIN credentials which is required to connect
to TD system.Sessions command is used to restrict the number of
sessions Fastload will make to connect to TD. Default is one session per
AMP.
.SESSIONS 4;
.LOGON 127.0.0.1/tduser,tduser;
Section 2
In
this section we are defining the table which we want to load from
Fastload. DROP commands are optional. There is no need to define the
structure of ERROR tables they’ll be created itself by Fastload.
drop table retail.emp_test;
drop table retail.emp_test_er1;
drop table retail.emp_test_er2;
create table retail.emp_test
(
emp_id integer not null,
emp_name varchar(50),
dept_id integer,
salary integer,
dob date format’yyyymmdd’
)
unique primary index(emp_id);
Section 3
In this section we give the BEGIN loading statement. As soon as Fastload receives this statement it starts PHASE 1.
BEGIN LOADING
retail.emp_test
ERRORFILES
retail.emp_test_er1, retail.emp_test_er2;
Section 4
RECORD
command is used to skip the starting rows from the data file. RECORD
THRU command is used to skip the last rows of data file. SET RECORD
command is used to define the records layout and the “,” is the
delimiter which we are using in our data file to separate columns.
.RECORD 1;
.RECORD THRU 3;
SET RECORD VARTEXT “,”;
Section 5
DEFINE
statement is used to define the structure of the data file. This should
be in accordance with the actual target table structure. Fastload
DEFINE statement allows only VARCHAR format.
DEFINE
emp_id (VARCHAR(9))
emp_name (VARCHAR(50))
dept_id (VARCHAR(9))
salary (VARCHAR(9))
dob (VARHAR(50))
Section 6
FILE command defines the data file path and name.
FILE = C:\fload_data.txt;
Section 7
INSERT
command is used to load the data file into actual target table. NOTE –
For DATE columns we can use the data conversion by the syntax given
below.
INSERT INTO retail.emp_test
(
:emp_id ,
:emp_name,
:dept_id ,
:salary,
:dob (format ‘yyyymmdd’)
);
Section 8
END LOADING ends PHASE 1 and starts the execution of PHASE 2. LOGOFF is required to close all the sessions created by Fastload.
END LOADING;
.LOGOFF;
How to run FastLoad Scrpts
fastload < Script Name >Fload.Log or
fastload < Script Name (It will display the log on the terminal)
Sample Script
.LOGON 127.0.0.1/tduser,tduser;
BEGIN LOADING tduser.EMP_FL
ERRORFILES TDUSER.EMP_FL_ER1,
TDUSER.EMP_FL_ER2
;
SET RECORD VARTEXT ",";
DEFINE
EmpNo (VARCHAR(15))
Name (VARCHAR(18))
Phone (VARCHAR(15))
DeptNo (VARCHAR(5))
Salary (VARCHAR(10))
YrsExp (VARCHAR(2))
FILE = C:\Users\Pundrik\Desktop\DATA\
insert into tduser.EMP_FL
(
EmpNo
,Name
,Phone
,DeptNo
,Salary
,YrsExp
)
values
(
:EmpNo
,:Name
,:Phone
,:DeptNo
,:Salary
,:YrsExp
)
;
end loading;
.logoff;
Fastload
does not support the multiset table because of restart capability ,
Because once the fastload jobfail, Till the fastload failes some number
of rows was sent to the AMPs. Now if you restart the FLOAD it would
start loading record from the last checkpoint and some of the
consecutive rows are sent for the second time.These will be caught as
duplicate rows are found after sorting of data.
This
restart logic is the reason that Fastload will not load duplicate rows
into a MULTISET table. It assumes they are duplicates because of this
logic. Fastload support Multiset table but does not support the
duplicate rows. Multiset tables are tables that allow duplicate rows.
When Fastload finds the duplicate rows it discards it. Fast Load can
load data into multiset table but will not load the duplicate rows.
Can I use “drop” statement in the utility “fload”?
YES,But
you have to declare it out of the FLOAD Block it means it should not
come between .begin loading,.end loading FLOAD also supports
DELETE,CREATE,DROP statements which we have to declare out of FLOAD
blocking the FLOAD Block we can give only INSERT
1st Error table data
select * from TDUSER.EMP_FL_ER1
duplicate record information
2nd Error table data
select * from TDUSER.EMP_FL_ER2
- Syntactical error in script
- Record parcel length does not match
- If the defining are using class structure length or input file, Data file not match, then we get the error
- Input number of values not matching with column names
Restarting FastLoad Job
Condition 1: Abort in Phase 1 - data acquisition incomplete.
Solution: Resubmit the script. FastLoad will begin from record 1 or the first record past the last checkpoint.
Condition 2: Abort occurs in Phase 2 - data acquisition complete.
Solution: Submit only BEGIN and END LOADING statements; restarts Phase 2 only.
Condition 3: Normal end of Phase 1 (paused) - more data to acquire, thus there is no 'END LOADING' statement in script.
Solution:
Resubmit the adjusted script with new data file name. FastLoad will be
positioned to record 1 or the first record past the last checkpoint.
Condition 4: Normal end of Phase 1 (paused) - no more data to acquire, no 'END LOADING' statement was in the script.
Solution: Submit BEGIN and END LOADING statements; restarts Phase 2 only.
No comments:
Post a Comment